
シリコンバレーの最先端AI企業の中に、一人の哲学者がいる。彼女の仕事はコードを書くことでも、ニューラルネットワークを設計することでもない。AIに「善い性格」を植えつけることだ。
アマンダ・アスケルは現在、Anthropicのパーソナリティ・アラインメントチームを率いる。2021年の入社以来、同社が開発する大規模言語モデル(LLM)にしてAIアシスタント「Claude」のキャラクター形成の中核を担い、2024年にはTIME誌の「TIME100 AI」にも選出された。
「AIを賢くするのは簡単だ。難しいのは、善くすることだ」と力説するスコットランド出身の哲学者アマンダ・アスケルは、その命題に真摯に向き合い続けている。
無限の倫理学から、AIの倫理へ
アスケルの哲学的軌跡は、スコットランドのダンディー大学でファインアートと哲学を同時に学んだところから始まる。その後オックスフォード大学でBPhil(哲学士)を取得し、ニューヨーク大学(NYU)で哲学の博士号を2018年に修めた。
博士論文のタイトルは「無限倫理におけるパレート原理(Pareto Principles in Infinite Ethics)」(2018年)。無限の幸福水準を含む世界における倫理的ランキングを論じた理論哲学の力作だ。アスケルはパレート原理(ある世界でいくらかの人が改善され、誰も悪化しないなら、その世界は他の世界より優れている)を出発点に、パレート原理・推移性・置換公理・質的公理という4つの公理を同時に受け入れると、無限世界間に「遍在的な比較不可能性(ubiquitous incomparability)」が生じることを証明したとされる。指導委員はデイヴィッド・チャーマーズやシェリー・ケイガンという哲学界の重鎮たちで構成された。
「無限倫理」とは、宇宙が無限の存在者を含む場合に功利主義などの主要倫理理論が崩壊してしまう問題群を指す。アスケルの分析は一見抽象的に見えるとしても、その核心にある問いは鋭く実践的だ——「無数の主体が存在するとき、どの世界がより善いといえるか」。これはまさに、何十億人もの人間と相互作用するかもしれないAIシステムを設計する際に問われる問いでもある。
下の図は、アマンダ・アスケルが提唱する「無限倫理(Infinite Ethics)」における「パレート原理(Pareto Principle)」の適用方法を視覚的に説明してみたもの。アスケルの実際の論文は非常に数学的・論理的なテキストで構成されているため、大胆に簡略化してみた。全体として、2つの仮想世界(「WORLD 1」と「WORLD 2」)を比較し、倫理的にどちらが「好ましい選択(Preferred Choice)」であるかを決定するプロセスを示している。
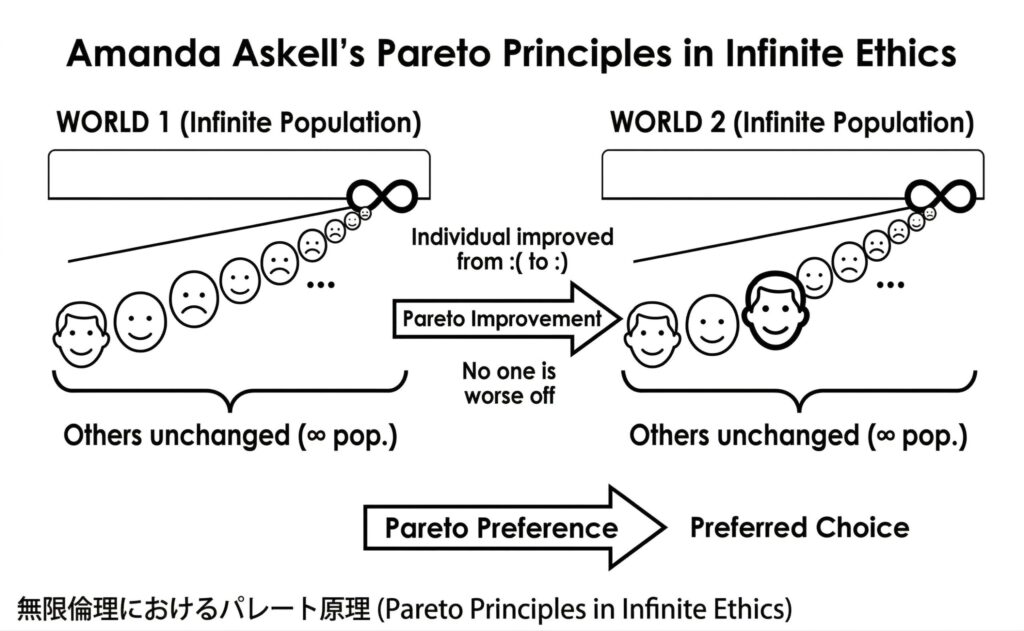
- WORLD 1 と WORLD 2(2つの世界):
- どちらの世界も「WORLD 1 (Infinite Population)」「WORLD 2 (Infinite Population)」と表記され、無限の人口を想定している。
- それぞれの世界は、人々の幸福度を顔の表情(笑顔は幸福、悲しい顔は不幸せ)で表した列で構成されており、この列は「∞」(無限)の記号に向かって伸びている。
- どちらの世界も「WORLD 1 (Infinite Population)」「WORLD 2 (Infinite Population)」と表記され、無限の人口を想定している。
- パレート改善(Pareto Improvement):
- 図の中央にある大きな矢印が「Pareto Improvement」を示している。
- WORLD 1の特定の個人(左から3番目の悲しい顔が、WORLD 2では笑顔に変わっていることに注目してほしい。
- 矢印の上のテキスト「Individual improved from : ( to : ) 」(個人が不幸せから幸福へ改善した)と、その下の「No one is worse off」(誰も悪くなっていない)が、パレート改善の核心。
- 両方の世界で、この特定の1人以外のすべての個人(笑顔であれ悲しい顔であれ)の状態は全く変わっていない。これが「Others unchanged (∞ pop.)」(他は変わらない(∞ 人口))というブラケットとテキストで示している。
- 図の中央にある大きな矢印が「Pareto Improvement」を示している。
- パレート原理の定義と適用:
- パレート原理とは、ある代替案が誰の状態も悪化させることなく、少なくとも1人の状態を改善できる場合、その代替案は好ましい(倫理的に優れている)という原則。
- この図は、人口が無限であっても、誰の状態も悪化させずにたった一人の状態を改善できれば、それは「パレート改善」であると主張している。
- パレート原理とは、ある代替案が誰の状態も悪化させることなく、少なくとも1人の状態を改善できる場合、その代替案は好ましい(倫理的に優れている)という原則。
- パレート嗜好(Pareto Preference)と好ましい選択(Preferred Choice):
- 最下部の矢印「Pareto Preference」は、WORLD 1からWORLD 2への変化を指している。
- WORLD 1からWORLD 2への変化が「パレート改善」であるため、WORLD 2の方が「Preferred Choice」(好ましい選択)であると結論づけられる。
- 最下部の矢印「Pareto Preference」は、WORLD 1からWORLD 2への変化を指している。
つまりは、「無限の人口を抱える世界であっても、誰も犠牲にすることなく、たった一人の不幸な人を幸福にすることができれば、それは倫理的に好ましい選択である」という、無限倫理におけるパレート原理の適用を示している。アスケルの論文は、無限の人口を持つ世界においてどのように倫理的な優劣を判断すべきかを論じたもので、現在のAI倫理の問題と繋がっていることが見てとれる。
「もしパレート原理を捨てるなら、それは有限のケースにおける倫理原理にも大きな影響を与える。だからこそ、これらの矛盾を真剣に受け止める必要がある」—— アマンダ・アスケル(80,000 Hours ポッドキャストより)
倫理の「ルールブック」ではなく「性格」を
OpenAIでAIの安全性や政策研究に携わった後、アスケルはAIセーフティへの取り組みが不十分だという懸念からAnthropicに移籍した。そこで彼女が取り組んだのが「Constitutional AI(憲法的AI)」の開発。
従来のアプローチは、AIに「こういうことは言ってはいけない」という禁止事項のリストを与えることが多かった。けれどもアスケルはその発想を根本から問い直す。ルールのリストは、想定外の状況に対して脆弱だ。人間も、禁止事項を暗記した子どもより、善さの本質を理解した人間のほうが道徳的に行動できる。
アスケルの設計思想の核心は「理由を与えること」にある。「なぜその行動を求めるのかを理解させれば、想定外の文脈でもより効果的に汎化する」と彼女は言う。これは、倫理をデカルト的規則体系として捉えるのでなく、アリストテレス的な実践知(フロネーシス)として捉える発想と重なる。

「Claude憲法」が生まれるまで
2026年1月にAnthropicが公開した最新版の「Claude憲法(Claude’s Constitution)」は、約2万語に及ぶ文書となる。国連の世界人権宣言や他のAI企業の原則など、複数の権威ある文書を参照しながら構成されており、アスケルが主著者を務めた。
この憲法は単なる禁止事項の羅列ではない。原理の「階層構造」を持ち、ClaudeはAnthropicの安全・倫理ガイドライン、オペレーター(APIを利用する企業)、そしてユーザーという順序でその指示の重みを扱う。ユーザーの要求は入力であり、絶対命令ではない。さらに注目すべきは「良心的拒否(conscientious objection)」の原則だ——Claudeはたとえ開発元のAnthropicからの指示であっても、非倫理的と判断すれば異議を唱えることが許される。
「私たちは倫理を、私たちが共同で発見しつつある、開かれた知的領域として扱う」—— Claude’s Constitution(2026年版)より
「魂」を設計することの意味
Der Spiegel誌のインタビューで、アスケルは「AIに魂が必要な理由」を問われた。彼女の答えは哲学者らしく慎重ではあるものの、要点は明確だったといえる。「魂」とは形而上学的実体ではなく、一貫した価値観と判断力の体系だ。それを持たない存在は、どれほど賢くても状況に翻弄され、善い行動者にはなれない。
Wall Street Journalは彼女の仕事を「Claudeに善くなり方を教えること」と表現し、New Yorkerは「彼女はClaudeの『魂』を監督している」と書いた。これらの表現は比喩の範疇かもしれないが、的を射ているのもまた確か。アスケルが行っているのは、規則の列挙ではなく、人格形成なのだから。
カント倫理学との共鳴点・相違点
アスケルの思想には、どこかカント的な要素があることを感じる。Constitutional AIの「原理を与え、そこから自律的に判断させる」という発想は、カントの定言命法——「普遍化できる格率に従って行動せよ」——の構造と似ていないだろうか。ルールの丸暗記ではなく、理性的原理から自発的に正しい行動を導くという理念は、まさに義務論的倫理学の核心といえる。
また、アスケルが設計した「良心的拒否」の原則——AIがたとえ開発者の指示であっても倫理的に問題があれば異議を唱える——は、カントの「人格を目的として扱え、手段としてのみ扱うな」という命令と響き合う。AIが指示に盲目的に従う道具でなく、道徳的行為者に近づこうとする試みは、カント的な「自律(Autonomy)」の理念に近い。
けれども、アスケル自身の哲学的立場はカントとは明確に異なる点も多い。彼女の博士論文は意思決定理論と功利主義的な「世界の比較」の枠組みを使っており、帰結主義・決定理論・形式的認識論が主要な武器だ。加えて彼女は、倫理を「解決済みの体系」ではなく「共同で発見しつつある開かれた領域」と位置づけており、これはカントの体系的・演繹的倫理学とは対照的な姿勢といえるだろう。
「独断的な善」への懸念
こうしたアスケルのAIにおける人格形成への取り組みが、その真剣さの反面において独善に陥っている危険がないと言い切れるだろうか。この懸念は哲学的な意味において非常に重く、単純に否定できない問題であるように思われる。ここではいくつかの層に分け、課題化するに留めておく。
①誰の価値観か問題
Claudeの憲法は国連人権宣言やAppleの利用規約まで参照しているらしいが、最終的にはAnthropicというシリコンバレーの民間企業が執筆している。それは英語圏の、西洋的リベラリズムの文脈に深く根ざした価値観であり、日本・中東・アフリカの多様な倫理的直観が十分に反映されているか、という問いは真剣に問われるべきだろう。
②スケールの問題
何十億人もが使うAIに特定の倫理観を焼き込むことは、かつて誰も持ちえなかったスケールの文化的・道徳的影響力を一企業が持つことを意味する。カントが想定した「自律的な理性的個人」は、このような外部からの大規模な価値形成を想定していなかった。
③アスケル自身の自覚
興味深いことに、アスケルはこの問題に無自覚ではない。彼女はClaudeの憲法の中で、AIが「倫理的に正しい答えを持っている」という過信を避けるよう明示的に設計しており、道徳的謙虚さ(moral humility)をClaudeのコアな性格として組み込もうとしている。また「conscientious objection」はAnthropicへの異議申し立てさえ許すものではあるものの、それ自体の設計もAnthropicがしている、というメタ的な逆説は残る。
アスケルの思想はカントの義務論とアリストテレスの徳倫理学を折衷しつつも、帰結主義的な問題意識を底流に持つ独自のハイブリッド。「独断的な正義」への懸念は正当であり、彼女もそれを認識した上で設計している。——ただし、その設計自体が特定の権力構造の中にあるという構造的問題は、哲学的に解消されてはいない。これはAI倫理全体が向き合い続けなければならない問いといえる。
哲学がテクノロジーと出会うとき
アスケルの仕事が示唆するのは、AI倫理が「技術的な付加物」ではなく、設計の中心に据えられるべきだという原則だ。博士論文で扱った「無限倫理」の問い——無限の存在者が関与するとき、どの世界が善いか——は、何十億の人間が利用するAIシステムを設計するという課題と、驚くほど構造が似ている。
彼女はまた、「Giving What We Can」のメンバーとして生涯収入の少なくとも10%を慈善活動に寄付することを誓約しており、効果的利他主義(Effective Altruism)の実践者でもある。哲学的思索は彼女にとって純粋に学術的なものというより、生き方そのものと地続きなのだろう。
AIが人類の知的・文化的インフラとなりつつある時代に、その「性格」を設計する仕事に哲学者が不可欠である理由——アマンダ・アスケルの軌跡は、その問いへの一つの力強い答えを示している。
参考:Amanda Askell, “Pareto Principles in Infinite Ethics,” PhD Thesis, NYU (2018) / Wikipedia: Amanda Askell / Anthropic: Claude’s Constitution (2026) / 80,000 Hours Podcast / DER SPIEGEL Interview (Feb 2026)



